
requests 是一個非常流行的 Python 套件,用於發送 HTTP 請求。它的設計目的是使 HTTP 請求變得簡單易用。以下是對 requests 套件的介紹:
requests 的接口直觀且易於使用,使得發送各種 HTTP 請求變得簡單。requests:pip install requests
& 分隔,並且以 ? 開始。數據對任何人都是可見的 ,這意味著敏感信息不應該通過 GET 方法傳輸。參數有長度限制 。import requests
# 直接在 URL 夾帶參數
response = requests.get('https://httpbin.org/get?key1=value1&key2=value2')
print(response.text) # 輸出網頁內容
# 參數不夾帶在URL
params = {'key1': 'value1', 'key2': 'value2'}
response = requests.get('https://httpbin.org/get', params=params)
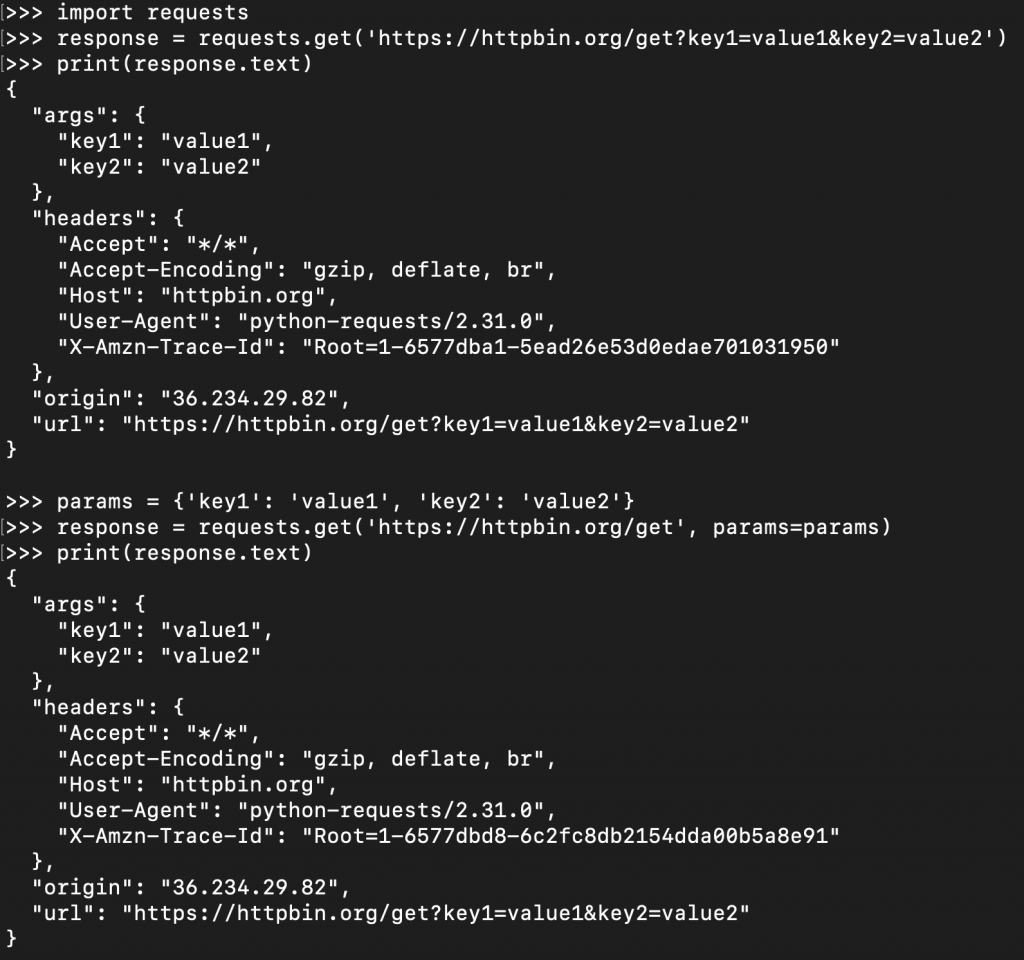
主體發送 。這意味著參數不會出現在 URL 中。適合傳輸敏感或私密數據 。沒有數據長度限制 ,適用於大量數據的傳輸。payload = {'key1': 'value1', 'key2': 'value2'}
response = requests.post('https://httpbin.org/post', data=payload)
print(response.text)
| 方法 | 說明 | 範例 |
|---|---|---|
| GET | 向指定的資源發送一個 HTTP GET 請求,用於請求數據。 | requests.get('https://httpbin.org', params={'key': 'value'}) |
| POST | 向指定資源提交數據進行處理請求。通常用於提交表單。 | requests.post('https://httpbin.org', data={'key': 'value'}) |
| PUT | 向指定資源位置上傳其最新內容。 | requests.put('https://httpbin.org', data={'key': 'value'}) |
| DELETE | 請求伺服器刪除指定的資源。 | requests.delete('https://httpbin.org') |
| PATCH | 對資源進行部分修改。 | requests.patch('https://httpbin.org', data={'key': 'value'}) |
在 requests 模組中,HTTP 請求的頭部(Headers)是關鍵的組成部分,用於在發送請求時向伺服器提供額外的上下文信息。頭部是由一系列的鍵值對構成的,它們定義了請求的許多重要屬性,如內容類型、用戶代理、認證信息等。
application/json、application/x-www-form-urlencoded。no-cache 或 max-age。requests 中設置頭部在 requests 中,可以在發送請求時通過 headers 參數自定義頭部:
headers = {
'User-Agent': 'MyApp/1.0',
'Accept': 'application/json',
'Authorization': 'Bearer <TOKEN>'
}
response = requests.get('https://httpbin.org', headers=headers)
Authorization 頭部時。| 參數 | 說明 | 範例 |
|---|---|---|
| User-Agent | 標識發出請求的客戶端類型。 | 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36' |
| Accept | 指定客戶端能夠接收的內容類型。 | 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8' |
| Content-Type | 發送數據到伺服器時的內容類型。 | 'Content-Type': 'application/json' |
| Authorization | 用於認證的憑據,如基本認證或令牌。 | 'Authorization': 'Bearer YOUR_TOKEN' |
| Accept-Encoding | 標識客戶端支持的內容編碼類型。 | 'Accept-Encoding': 'gzip, deflate, br' |
| Connection | 控制是否保持網絡連接的活躍。 | 'Connection': 'keep-alive' |
| Host | 指定發送請求的目標伺服器。 | 'Host': 'example.com' |
| Referer | 指示請求的原始資源的地址。 | 'Referer': 'https://www.example.com' |
| Cookie | 從客戶端傳送到伺服器的 Cookie。 | 'Cookie': 'name=value; name2=value2' |
當使用 requests 模組進行 HTTP 請求時,伺服器的回應(即回傳的資料)可以通過 Response 對象來訪問和解析。以下是如何解析 requests 回傳的資料的不同方面:
在使用 requests 模組進行 HTTP 請求時,伺服器會返回不同的 HTTP 狀態碼,以表示請求的結果。以下是一些常見的 HTTP 狀態碼及其說明:
response = requests.get('https://example.com')
status_code = response.status_code
| 代碼 | 說明 |
|---|---|
| 200 | OK - 請求成功處理。 |
| 201 | Created - 請求成功並創建了新的資源。 |
| 202 | Accepted - 請求已被接受進行處理,但處理尚未完成。 |
| 204 | No Content - 請求成功,但沒有新的內容返回。 |
| 301 | Moved Permanently - 請求的資源已永久移動到新位置。 |
| 302 | Found - 請求的資源臨時從不同的 URI 回應。 |
| 400 | Bad Request - 伺服器無法或不會處理請求(客戶端錯誤)。 |
| 401 | Unauthorized - 認證失敗或未提供認證。 |
| 403 | Forbidden - 伺服器拒絕請求。 |
| 404 | Not Found - 找不到請求的資源。 |
| 405 | Method Not Allowed - 不允許使用請求中指定的方法。 |
| 500 | Internal Server Error - 伺服器遇到了不知道如何處理的情況。 |
| 502 | Bad Gateway - 獲取請求的伺服器,從上游伺服器收到無效回應。 |
| 503 | Service Unavailable - 伺服器目前無法使用(超載或停機維護)。 |
| 504 | Gateway Timeout - 未能及時從上游伺服器或輔助伺服器收到請求。 |
這些狀態碼是根據 HTTP 標準定義的,代表了伺服器對 HTTP 請求的不同回應。在使用 requests 或其他 HTTP 客戶端進行網絡請求時,正確理解這些狀態碼對於處理不同的回應非常重要。
text_content = response.text
binary_content = response.content
json_data = response.json()
headers = response.headers
encoding = response.encoding
response.encoding = 'utf-8'
cookies = response.cookies
history = response.history
通過以上方法,您可以根據需要從 requests 的回應中提取和處理各種數據。在實際的應用中,根據伺服器回應的特點和需求選擇合適的解析方式非常重要。
requests 時應注意處理可能出現的異常,如 ConnectionError、Timeout 等。with 語句管理回應對象,以確保釋放網絡資源。requests 進行網路爬蟲時,應尊重目標網站的 robots.txt 規則,並確保符合相關法律法規。requests 的功能強大且使用方便,是 Python 網路程式設計和網路爬蟲的重要工具之一。
HTTPBin 是一個線上服務,用於測試 HTTP 請求和回應。它提供了一系列端點,每個端點都展示了特定類型的行為,使得開發者可以測試和理解 HTTP 協議的不同方面。HTTPBin 對於學習 HTTP 協議、調試和測試客戶端(如網頁瀏覽器和 HTTP 客戶端庫)非常有用。
/ip:返回請求者的 IP 地址。/user-agent:返回請求者的 User-Agent 信息。/headers:返回請求的 HTTP 頭部信息。/get:返回 GET 請求數據。/post:返回 POST 請求數據。/status/:code:返回一個特定的 HTTP 狀態碼。/response-headers:返回自定義的回應頭部。/redirect/:n:重定向到一個新的 URL,次數為 n。/cookies:返回請求中的 cookies。/delay/:n:在回應之前等待 n 秒。總之,HTTPBin 是一個實用的工具,無論是對於學習 HTTP 協議的新手還是需要測試和調試 HTTP 請求的經驗豐富的開發者。
原始碼
Requests 程式 抓取網頁資訊import requests
response = requests.get('https://tw.stock.yahoo.com/')
print(response.text[0:1000]) # 印出前1000個字
在開始使用 requests 模組之前,建議先對 HTTP 傳輸協定有一定的了解和認識。實際上,requests 模組是一個建立在 HTTP 協定之上的工具,它的主要功能是協助我們通過網絡請求來獲取資料,無論是 HTML 頁面內容還是 JSON 格式的數據。因此,對 HTTP 協定的基本原理和操作有所熟悉,將有助於您更有效地使用 requests 模組,並能更好地理解網路請求和響應的過程。這包括瞭解不同的 HTTP 方法、狀態碼、請求頭部以及如何處理響應數據等。掌握這些基礎知識,將為您在網絡程式開發領域的進一步學習和實踐打下堅實的基礎。
分享所學貢獻社會
[Python教學]開發工具介紹
[開發工具] Google Colab 介紹
[Python教學] 資料型態
[Python教學] if判斷式
[Python教學] List 清單 和 Tuple元組
[Python教學] for 和 while 迴圈
[Python教學] Dictionary 字典 和 Set 集合
[Python教學] Function函示
[Python教學] Class 類別
[Python教學] 例外處理
[Python教學] 檔案存取
[Python教學] 實作密碼產生器
[Python教學] 日期時間
[Python教學] 套件管理
[Python爬蟲] 網路爬蟲
[Python爬蟲] 分析目標網站
[Python爬蟲] 發送請求與解析網站內容
最後最後有一件小小的請求,請大家幫我填寫一下問卷,
讓我們知道你想上怎麼樣課程,感激不盡。
問卷這邊
Facebook 粉絲頁 - TechMasters 工程師養成記
[Python爬蟲] 網路爬蟲
[Python爬蟲] 分析網站
[Python爬蟲] Requests 模組
 pellok
pellok

 iThome鐵人賽
iThome鐵人賽